1Google DeepMind 2Google Research 3Cornell University 4Google 5Stanford University
Intro
Given an observation of a complex system, what number(s) will it produce?
Historically, entire fields have resorted to traditional tabular regression which represents all information as tables, or precisely, normalized fixed-dimensional vectors. But the world isn’t a table. Tabular methods can’t be applied to data possessing arbitrary sequence lengths, such as code, logs, or free-form text.
We instead represent numeric prediction as a sequence-to-sequence problem.
Method Overview
A compact encoder-decoder converts, or transduces, from the space of all observations into another: the space of all real numbers.
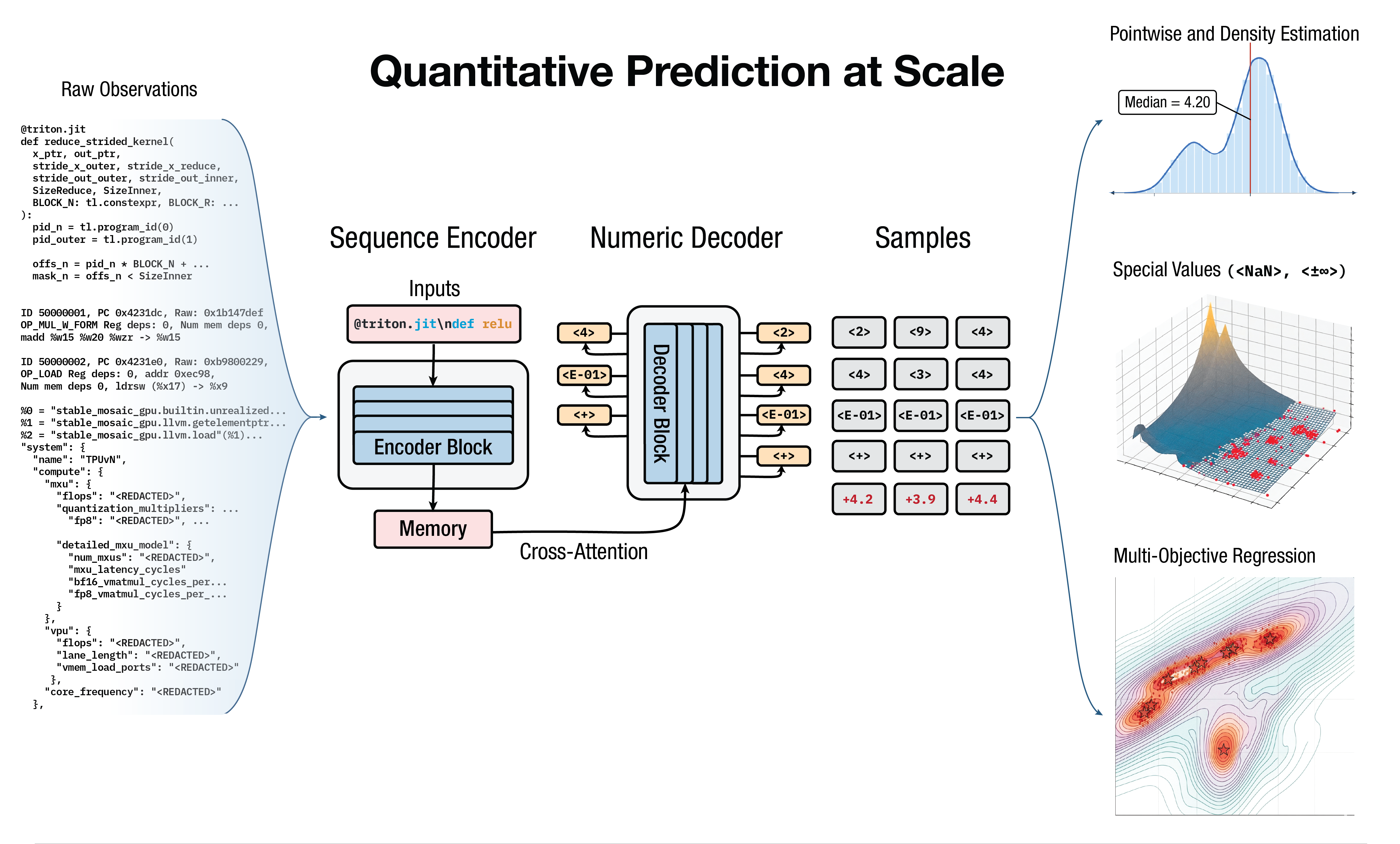
By:
- Expressing token-by-token, input observations $x$ can be represented as-is, and output numbers $y$ can stay unnormalized.
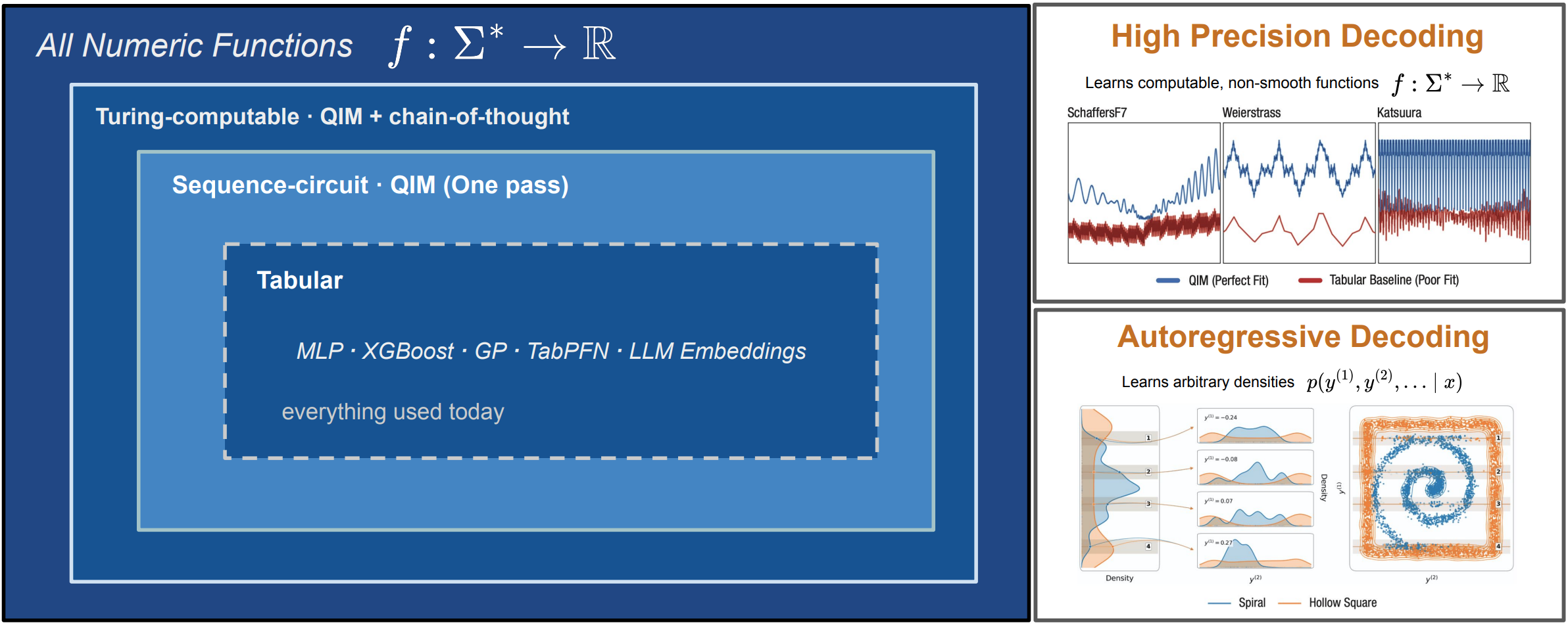
- Using cross-attention (instead of compressive embeddings attached to a tabular head), information is preserved and even allows approximating any computable function.
- Training with cross-entropy loss over numeric targets, we smoothly learn any (possibly multi-objective) density $p(y \mid x)$ to express epistemic and aleatoric uncertainty properly.
- Scaling up and fine-tuning, we can perform enormous amounts of transfer-learning over any $(x,y)$ data pairs.
At inference, decoding numbers allows us to perform intuitive, or inductive reasoning about the world.
Applications
Across 10 different high-impact scientific and industrial problems spanning experimental design, code execution, healthcare, and physics, each application achieves at least one of:
- A new predictive capability not previously demonstrated.
- Outperforms SoTA without domain-specific architecture or feature engineering.
- Near-perfect simulation with at orders of magnitude lower cost.
- Unified data scaling: Massive transfer-learning across different tasks.
Predicting ML Experiments from Code
Kaggle Experiment Scores
Hyperparameter Optimization Reduction
Up to 100x fewer experiments needed
Simplifying Neural Architecture Search
Zero expertise needed, achieve 48% against SoTA
GPU Kernel Optimization
16-100x fewer trials needed
Static Analysis for Memory
24+ different languages covered
CPU Microarchitecture Simulation
Explore $10^{20}$ hardware configurations quickly
TPU/LLM Pareto Frontier Generation
Latency + throughput tradeoffs for TPU/LLM co-design
Data Center Efficiency
Prediction from raw telemetry logs
Nuclear Fusion Surrogates
Novel inputs from raw code and configs
Cancer Survival Prediction
Combine 9+ modalities into one model










Code Availability
Code can be found in the open-source package (github.com/google-deepmind/regress-lm). The default model trains on a single H100 GPU with inputs of up to 32K tokens, and can be further made to run on consumer hardware by using single-layer encoders and decoders.
We provide the following Colabs and pretrained checkpoints for flagship result demos:
- Synthetic Density: synthetic_density_demo.ipynb.
- ML Experiments from Code (Kaggle): kaggle_demo.ipynb.
- Triton GPU Kernels: triton_demo.ipynb.
Pretraining data sources are listed in the paper.
Acknowledgements
We thank Yutian Chen, Chen Sun, Vinh Tran, Alexander Rush, Michael Brenner, Dara Bahri, Yifeng Lu, Jonathan Lai, and Zhiyu Wei for early feedback, reviewing, and support of the manuscript.
We further thank Chen Liang, Oscar Li, Fred Zhang, Xuezhi Wang, Erik Lin, Esteban Real, Bangding (Jeffrey) Yang, Jarrod Kahn, Yiding Jiang, Samuel Sokota, Yan (Bill) Huang, Victor Reis, Phitchaya Mangpo Phothilimthana, Jörg Bornschein, Tejas Karkhanis, Amir Yazdan Bakhsh, Sami Abu-El-Haija, Erik Lin, Tung Nguyen, Eric Tang, Arissa Wongpanich, Shane Gu, Yingjie Miao, Qiuyi Zhang, Uri Alon, Shao-Hua Sun, Kuang-Huei Lee, Adrian N. Reyes, Zi Wang, Xinyun Chen, Aviral Kumar, Ke Xue, Rong-Xi Tan, Chansoo Lee, Michal Lukasik, Sagi Perel, and Daniel Golovin for relevant discussions.
We finally thank Parthasarathy Ranganathan, Amin Vahdat, Craig Donner, Martin Dixon, Shibl Mourad, Zoubin Ghahramani, and Benoit Schillings for support.
Citation
If you find this work useful, please cite:
Disclaimer: This is not an officially supported Google product.